IDA project
Year: 2020
Focus: UX research
Skills: Qualitative research, Persona, Customer Journey Map, Competitive Analysis
It's a class project collaborated with Microsoft IDA team, aiming to analyze the user experience on IDA and give improvement proposal. IDA, is the first AI-powered platform for journalists and publishers from Microsoft Azure. It aims to help journalists find the specific content they need quickly. I worked with other 4 classmates and finally proposed 3 improvement ideas to Microsoft IDA team.
Research question
Each team was assigned to a specific question on IDA. This is what we got:
In what ways can we use different AI and ML techniques to continue to build out IDA pipeline processing?
User research
Due to limited time, we reviewed great amount of literature and conducted an informal interview with a journalist. First, we brokedown the elements of journalism to understand their working pattern and key components. After that, we paid attention on what would be the potential harm in the working process.



Key findings
We found that the process of making a quality journalism requires times and efforts on research and data collection. However, the news cycle is too short to screen whether the information is right or not. The pressure to keep updating causes the problem that journalists might overlook the credibility of information's source.
The hidden worries of fake news need to be improved. We can use AI/ML to mitigate this problem on IDA.
Analysis
Due to our research question focusing on techniques, we discussed much on functionality instead of UI. To analyze the site and its features and functions, we brokedown IDA's every touchpoint page by page. We believe IDA wants to emphasize its search engine and open datasets. Based on these two features, we sorted out the customer journey, stakeholders, and competitive analysis.
Break down the site
Customer Journey Map

Stakeholder analysis

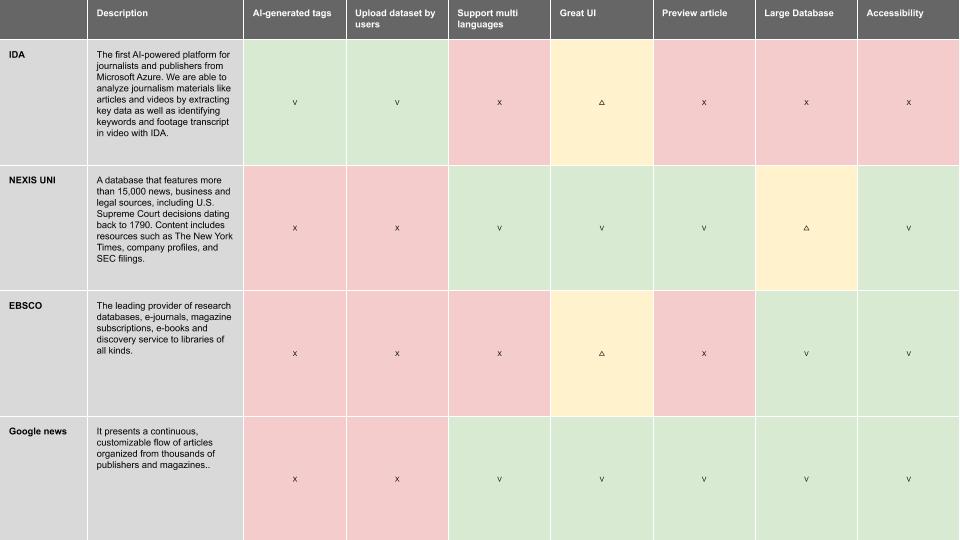
Competitive analysis
Insights
1. Search is the key
Users aim to find related content on IDA in a short time. Although it does provide filters, there're no preview or hightlight on the results page. It'll be time-consuming to figure out the document they want.
2. Concerns on open-dataset
What makes IDA stand out is that users are able to upload any files including images, videos, text...on this platform. IDA can autogenerate tags from the contents which helps user to find data easier. Yet unreliable resources might come along if IDA don't provide any screening system.
3. Accessibility design
In the results of competitve anaysis, we found all of them emphasized the improtance of accessibility especially for a searching engine. Obviously, it's necessary to make the IDA accessible.
Needs and painpoints
Needs
Creating a well-researched, contextualized report in a short period of time.
Painpoints
- It's time-consuming to manage data
- False information might be included
- Lack of accessibility
Improvement suggetions
Content highlighter and preview
With Neuro-Linguistic Programming, IDA can identify data-related facts based on the key word from input, which means that IDA will highlight the potential paragraphs that users are looking for in the articles. And of course, users can preview the highlight part of articles on search results page.

Fake news filter
In order to ensure the diversity of IDA's database, we placed the auto-generated fake news filter when users preview or review the file instead of blocking the file from uploading in the beginning. IDA provides an index for user to decide how reliable the data is.

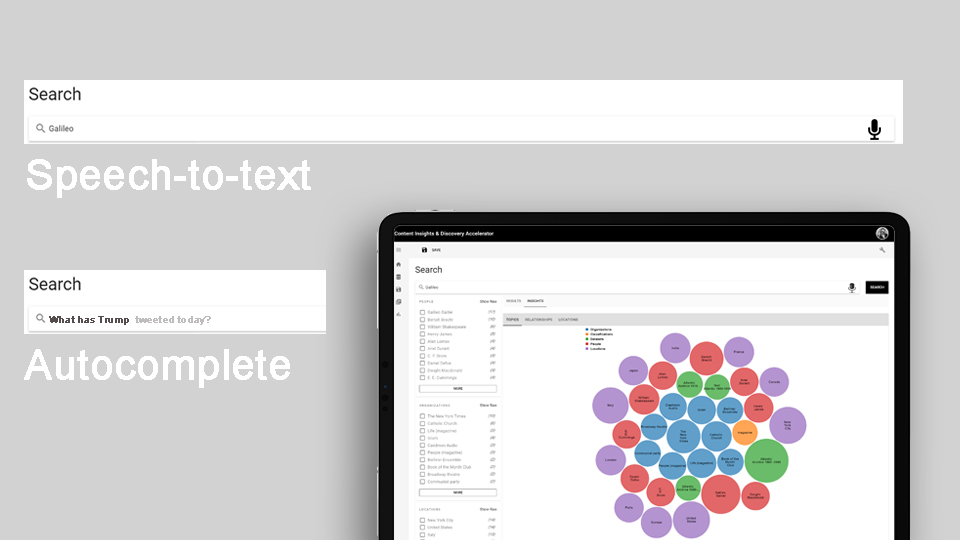
Speech-to-text, voice over, and autocomplete
Optimized the searching system and added voice over founction to improve the level of accessibility.